20
May 2016

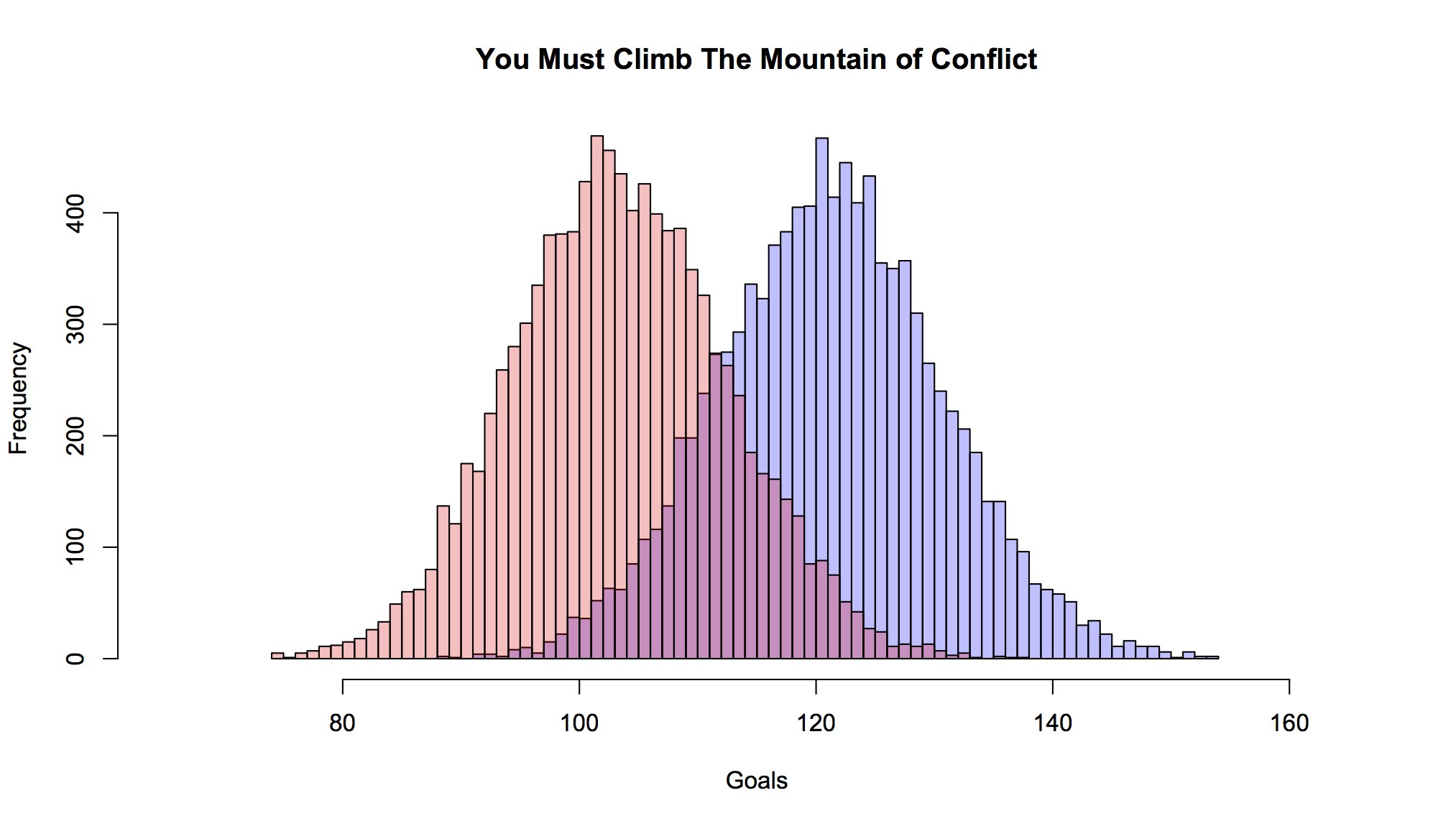
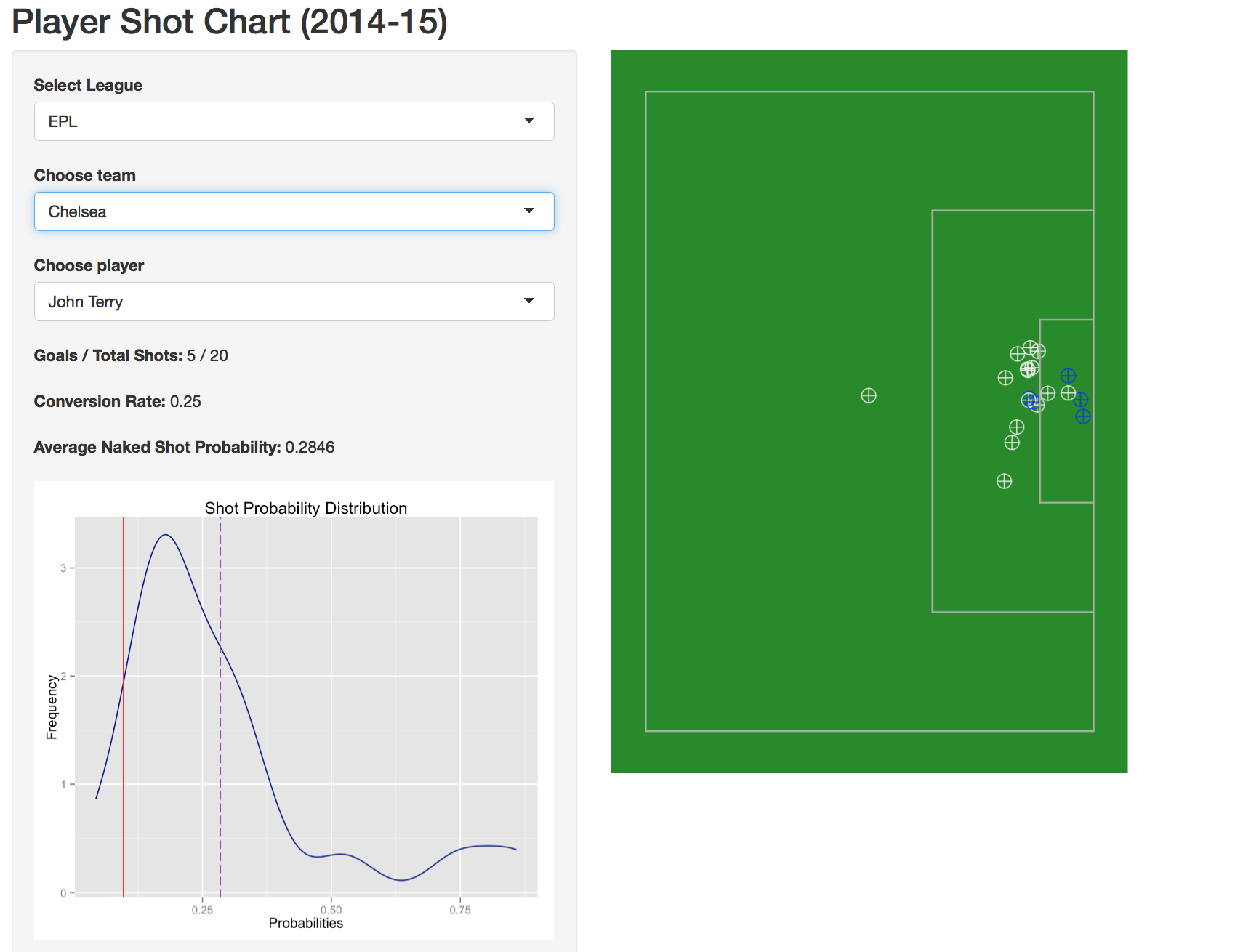
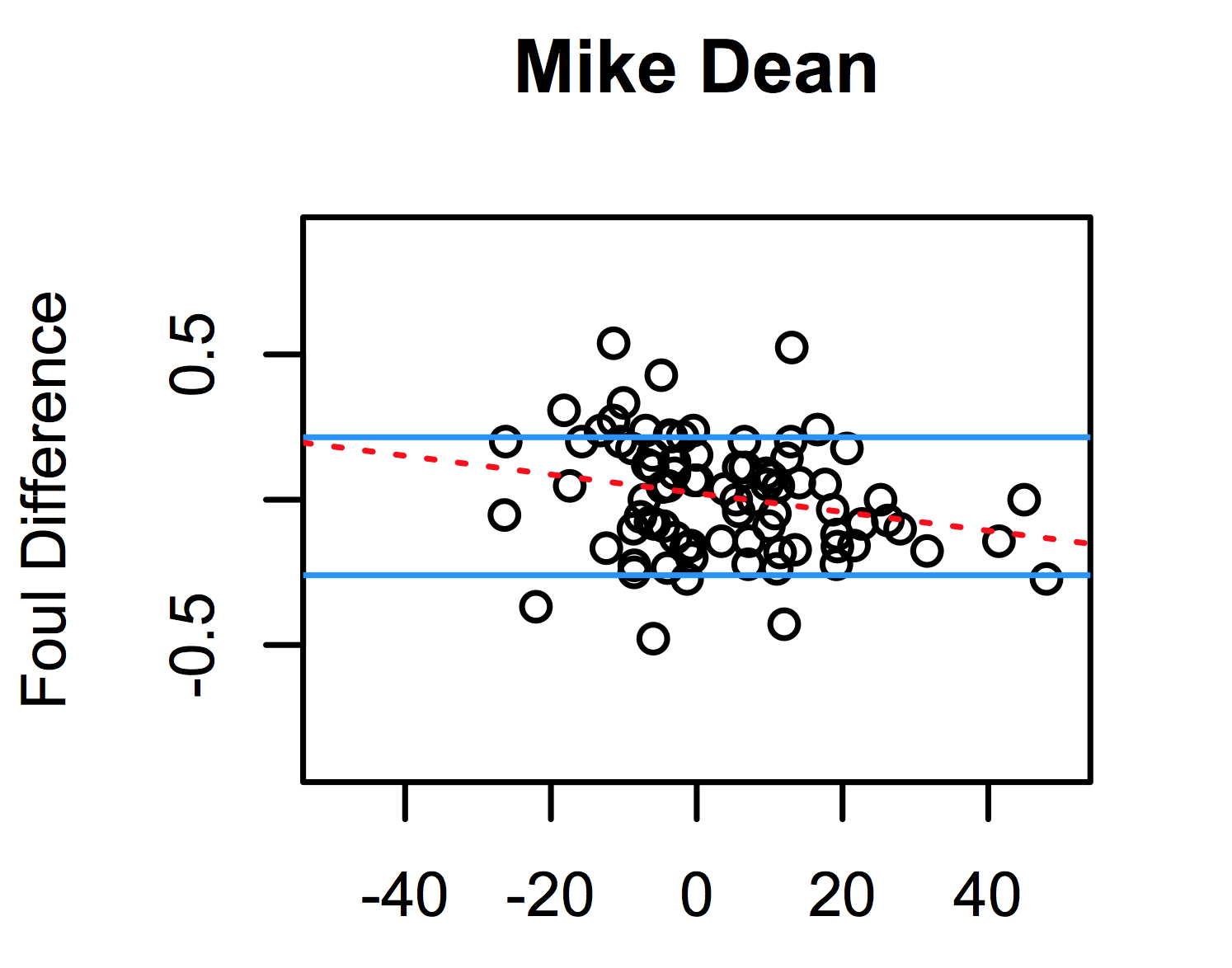
At some point late in the EPL season I could tell when Harry Kane scored more than one goal in a game without having to watch him play. That’s because a couplathree people would Tweet into my timeline a shot1 at me with a link to this. It’s the piece I did for FiveThirtyEight at […]